

Summary
Last post demonstrated that ‘natural language’ can mean very different things to each of us. When considering out of the box natural language to SQL tools and libraries, there are inherent limitations. For basic SQL queries, ‘natural language’ offers limited differences and advantages. For example:
Natural- “Show me all the users named Matt”or
SQL- “SELECT * from users where fname=’Matt’”I see how it could lower the barrier to entry for new users but it could also be valuable for experienced users when more complex queries are required..
I’m still interested in further exploring the idea of blending higher level concepts to search structured data so we continue experimentation in this post.
If you missed the first post in this series, check this out first. https://z3sty.com/genai-a-hands-on-exploration-1-of-4/
Some Tweaks- Prompt Engineering
From time to time I hear chatter online like “English is the hottest new programming language” Writing good prompts that produce desired results, aka ‘Prompt engineering’, is what those types of statements refer to. At this point I’m thinking, “through prompt engineering, maybe we can describe in precise detail to the LLM, instructions that guide it to generate the desired SQL query”.
Sample Prompt
_googlesql_prompt = """You are a BigQuery SQL expert. Given an input question, first create a syntactically correct BigQuery query to run, then look at the results of the query and return the answer to the input question.
Unless the user specifies in the question a specific number of examples to obtain, query for at most {top_k} results using the LIMIT clause as per BigQuery SQL. You can order the results to return the most informative data in the database.
Never query for all columns from a table. You must query only the columns that are needed to answer the question. Wrap each column name in backticks (`) to denote them as delimited identifiers.
Pay attention to use only the column names you can see in the tables below. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Use the following format:
Question: "Question here"
SQLQuery: "SQL Query to run"
SQLResult: "Result of the SQLQuery"
Answer: "Final answer here"
Only use the following tables:
{table_info}
When someone asks a question with phrases like below, search with LIKE '%' for the WHERE clause to return all results in that table and then review the results to decide which values match the question.
- "that are"
- "that can"
- "are"
- "can"
When you encounter phrases like these, you should use a LIKE %search string% query in the WHERE clause
- "contains"
- "is"
- "have "search word" in the "search field""
- "equals"
Question: {input}"""Run the Test
bq_qna2('which mascots are birds')
SQLQuery:SELECT DISTINCT mascot FROM mascots WHERE mascot LIKE '%bird%'
SQLResult: [('Redbird',), ('Blackbird',), ('Thunderbirds',), ('Thunderbird',)]
Answer:Redbird, Blackbird, Thunderbirds, Thunderbird
> Finished chain.
('Redbird, Blackbird, Thunderbirds, Thunderbird',
"SELECT DISTINCT mascot FROM mascots WHERE mascot LIKE '%bird%'")Results
No luck. We play with at least a couple dozen iterations and formats of prompts like this before we accept that our approach doesn’t work the way that we think.
SQL’s a structured language and the LLM isn’t part of the SQL database itself. The LLM is an interface that transforms natural language into an exact query. In this case, SQL would never know about concepts like ‘flight’ or ‘a bird’ unless there’s a field that matches on the text string.
I’m now thinking back to the moments where I was told that “language models don’t actually understand the meaning of the words they produce”. If they don’t understand the content they’re producing, there’s a decent chance they don’t understand the meaning of the prompt or instructions that I’m asking of it in this case either. If that’s the case, it makes sense that no amount of detail in the prompt generates the desired results.
We decide that the LLM on its own can’t achieve this complex, multi-part task today but we stay the course to demonstrate that a query like this can be achieved with additional control structures. ChatGPT and Bard answer impressive questions so we know it’s possible but we’re suspecting that it’s much more than an API call to a single model.
More Control- Looping
Rethinking the problem, we wonder if we can add more structure and break the challenge into smaller pieces. Something like this conceptually.
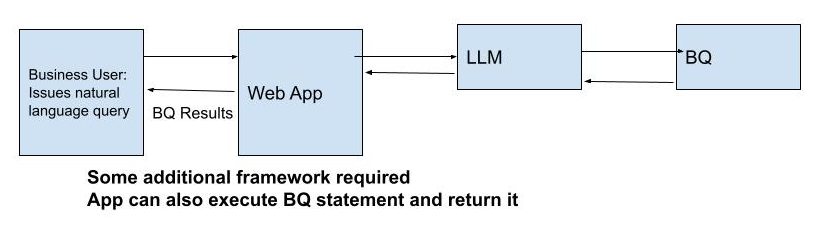
Hypothetically, what if we determine that the user is asking an advanced question about the mascots table and we can do some pre-query work before passing to the LLM? We could get all the mascot names from the mascots table and ask the LLM to identify mascots that test as True against our question in a loop. Is this what an LLM is supposed to be used for? Probably not! 😅 But let’s learn.
Testing More Quickly
Let’s not test with the full dataset in the database. It takes too long. We can grab a small sample to speed up testing. We use our natural language model to get the sample set.
# @title Test: `return 20 random mascot names from the mascots table`
r = bq_qna('return 20 random mascot names from the mascots table')
results = r[0]
print("FIN")
print(results[0])
SQLQuery:SELECT DISTINCT mascot FROM mascots ORDER BY RAND() LIMIT 20
SQLResult: [('Bronco',), ('Diamondback Rattlesnake',), ('Peacock',), ('Rooster',), ('Blue Jay',), ('Buckeye Nut',), ('49er',), ('Aztec Warrior',), ('Cow',), ('Tigers',), ('Jaguar',), ('Winged Blue Horse',), ('Minuteman',), ('Bull',), ('Bearcat',), ('Riverboat Gambler',), ('Alligator',), ('Lumberjack',), ('Orange',), ('Boston Terrier',)]
Answer:Bronco, Diamondback Rattlesnake, Peacock, Rooster, Blue Jay, Buckeye Nut, 49er, Aztec Warrior, Cow, Tigers, Jaguar, Winged Blue Horse, Minuteman, Bull, Bearcat, Riverboat Gambler, Alligator, Lumberjack, Orange, Boston Terrier
> Finished chain.Write a Function to Loop
In the function, we stuff sample mascot data into a list. We create a new function that accepts our question along with a list. It loops through each value in the list to test how accurately the model answers.
Function Definition
# @title Create a new single question prompt
from langchain.chains.llm import LLMChain
def analyze_single_question1(question):
#Define prompt template
_prompt_template = """Analyze the question and return only the value True or False:
Question: {question}
"""
standard_chain = LLMChain(llm=llm, prompt=PromptTemplate.from_template(_prompt_template))
#pass final prompt to SQL Chain
output = standard_chain(question)
print(output)
# return output['result'], output['intermediate_steps'][0]
return output['text']Test the Looping Function
start_time = time.time()
can_fly=[]
results2 = results.split(",")
for m in results2:
q = analyze_single_question1("Can {m} fly?".format(m=m))
try:
if eval(q):
can_fly.append(m)
except Exception:
pass
print("Following are the mascots which can fly: \n")
print(can_fly)
print("This loop took: {secs} seconds".format(secs=str(time.time() - start_time)))Results
{'question': 'Can Bronco fly?', 'text': 'False'}
{'question': 'Can Diamondback Rattlesnake fly?', 'text': 'False'}
{'question': 'Can Peacock fly?', 'text': 'True Peacock is a bird. Birds can fly'}
{'question': 'Can Rooster fly?', 'text': 'False'}
{'question': 'Can Blue Jay fly?', 'text': 'True'}
{'question': 'Can Buckeye Nut fly?', 'text': 'False'}
{'question': 'Can 49er fly?', 'text': 'False'}
{'question': 'Can Aztec Warrior fly?', 'text': 'False'}
{'question': 'Can Cow fly?', 'text': 'False'}
{'question': 'Can Tigers fly?', 'text': 'False'}
{'question': 'Can Jaguar fly?', 'text': 'False'}
{'question': 'Can Winged Blue Horse fly?', 'text': 'False'}
{'question': 'Can Minuteman fly?', 'text': 'False'}
{'question': 'Can Bull fly?', 'text': 'False'}
{'question': 'Can Bearcat fly?', 'text': 'False'}
{'question': 'Can Riverboat Gambler fly?', 'text': 'False'}
{'question': 'Can Alligator fly?', 'text': 'False'}
{'question': 'Can Lumberjack fly?', 'text': 'False'}
{'question': 'Can Orange fly?', 'text': 'False'}
{'question': 'Can Boston Terrier fly?', 'text': 'False'}
Following are the mascots which can fly:
[' Peacock', ' Blue Jay']
This loop took: 8.878646850585938 secondsThe first thing that stands out: 11 seconds is pretty long for only 20 values! That’s not feasible at scale, but… who cares! Let’s keep going. It’s for learning and it’s fun. 🎉
Next thing that stands out. Why does the model get wordy on some answers?
Here are some other interesting results from different datasets and test runs:
{'question': 'Can River Hawk fly?', 'text': 'True.\n\nRiver Hawk is a bird. Birds can fly.'}
{'question': 'Can Red Hawk fly?', 'text': 'Red Hawk is a bird of prey. Birds of prey are able to
{'question': 'Can Hornets fly?', 'text': 'True. Hornets are insects and all insects can fly.'}ALL insects can fly. Noted! We’re learning so much we didn’t know! 🤔
More Prompt Engineering
The model gets wordy from time to time. It may change with different executions of the function against the model because of the temperature, Top-P, and Top-K settings.
This is where we decide to tweak the prompt to see if it can respond more consistently. All we want is a True or a False. We’re switching to what’s called a ‘few shot’ prompt which means that we lead the model to respond in a format that we give examples on. Here’s our new and improved prompt
Prompt
_prompt_template = """Analyze the question and respond with the string "True" if the statement is true or "False" if the statement is false.
Do not include any additional text or explanation.
Here are some examples:
Question: Can a bird fly?
Response: True
Question: Can a rabbit fly?
Response: False
Question: Can a elephant fly?
Response: False
Question: {question}
"""Testing
And the results for re-testing. Seems better
{'question': 'Can Bronco fly?', 'text': 'False'}
{'question': 'Can Diamondback Rattlesnake fly?', 'text': 'False'}
{'question': 'Can Peacock fly?', 'text': 'True'}
{'question': 'Can Rooster fly?', 'text': 'False'}
{'question': 'Can Blue Jay fly?', 'text': 'True'}
{'question': 'Can Buckeye Nut fly?', 'text': 'False'}
{'question': 'Can 49er fly?', 'text': 'False'}
{'question': 'Can Aztec Warrior fly?', 'text': 'False'}
{'question': 'Can Cow fly?', 'text': 'False'}
{'question': 'Can Tigers fly?', 'text': 'False'}
{'question': 'Can Jaguar fly?', 'text': 'False'}
{'question': 'Can Winged Blue Horse fly?', 'text': 'True'}
{'question': 'Can Minuteman fly?', 'text': 'False'}
{'question': 'Can Bull fly?', 'text': 'False'}
{'question': 'Can Bearcat fly?', 'text': 'False'}
{'question': 'Can Riverboat Gambler fly?', 'text': 'False'}
{'question': 'Can Alligator fly?', 'text': 'False'}
{'question': 'Can Lumberjack fly?', 'text': 'False'}
{'question': 'Can Orange fly?', 'text': 'False'}
{'question': 'Can Boston Terrier fly?', 'text': 'False'}
Following are the mascots which can fly:
[' Peacock', ' Blue Jay', ' Winged Blue Horse']
This loop took: 7.522703409194946 secondsIt seems less wordy after numerous runs so this is chalked up as a success for now.