


Improve Response Times
7-12 seconds for 20 results doesn’t work well once we’re talking 100’s, 1000’s or more entries. How can it be sped up? Right now it’s a single item per call to the model. It makes sense to try and batch the requests. Let’s give it a try.
Batch Function
# @title New Function- Batch analyze to reduce time and number of calls/tokens (FAIL)
def analyze_list_question1(question, mylist):
# print(mylist)
#Define prompt template
_prompt_template = """
Answer true or false for each item from the comma seperated list below against the question.
Question: {question}
List {provided_list}
If the result is true for an item, add the item to a new comma separated string and return the string as the answer
Answer:
"""
standard_chain = LLMChain(llm=llm, prompt=PromptTemplate.from_template(_prompt_template))
#pass final prompt to SQL Chain
output = standard_chain({'question': question, 'provided_list': mylist})
print("########")
print(output)
# return output['result'], output['intermediate_steps'][0]
return output['text']Results
Following are the mascots which can fly:
Peacock, Rooster, Blue Jay, Winged Blue Horse
This loop took: 0.47997474670410156 secondsIt seems to work! Oh wait, looking at the past results it’s missing Peacock. The response time is MUCH better though!
Explore the ‘Logic’ Behind the Model
At this point, I want to learn more about the model’s decision making. Why does it miss ‘peacock’. Maybe peacocks don’t meet its formal definition of ‘flying’ since they can only fly short distances? Let’s tweak the prompt to ask it to explain why it makes the choice that it does.
Function Definition
# @title Test new batch function
start_time = time.time()
print(results)
matched_test = analyze_list_question2(question="Which of these are able to fly?", mylist=str(results.replace(',', '\n')))
print("Following are the mascots which can fly: \n")
print(matched_test)
print("This loop took: {secs} seconds".format(secs=str(time.time() - start_time)))Results
Following are the mascots which can fly:
False Bronco is a horse and horses cannot fly.
False Diamondback Rattlesnake is a snake and snakes cannot fly.
True Peacock is a bird and birds can fly.
True Rooster is a bird and birds can fly.
True Blue Jay is a bird and birds can fly.
False Buckeye Nut is a nut and nuts cannot fly.
False 49er is a person and people cannot fly.
False Aztec Warrior is a person and people cannot fly.
False Cow is a mammal and mammals cannot fly.
False Tigers are mammals and mammals cannot fly.
False Jaguar is a mammal and mammals cannot fly.
True Winged Blue Horse is a horse and horses can fly.
False Minuteman is a person and people cannot fly.
False Bull is a mammal and mammals cannot fly.
False Bearcat is a mammal and mammals cannot fly.
False Riverboat Gambler is a person and people cannot fly.
False Alligator is a reptile and reptiles cannot fly.
False Lumberjack is a person and people cannot fly.
False Orange is a fruit and fruits cannot fly.
False Boston Terrier is a dog and dogs cannot fly.
This loop took: 1.9387414455413818 secondsIn bold above are some of its statements that I find interesting. The LLM doesn’t seem to always understand what’s asked or it’s operating on some flawed ‘knowledge’.
Implications
I find myself returning to the possibility that LLM’s may not understand the meaning of the words in the same way as humans do. From what I’ve read on the fundamentals on how LLMs were created, they’re using statistical methods to predict text based on the written text that it’s been exposed to or ‘trained’ upon.
“Lie with the dogs, wake up with ____” The model looks at the preceding words to predict the next word(s) where the blank is. In this case, the answer could be chiggers, dogs, cats, umbrellas, or any noun to fit the grammar structure. Many experienced English speakers may recall from experience that the most appropriate answer in this case is ‘Fleas’ right? If you didn’t guess fleas, you probably weren’t ‘trained’ on this phrase from your past experiences.
While LLMs may have started with a basic statistical analysis to solve problems, it seems possible that they could have discovered additional patterns that aren’t as obvious.
Batch Function Accuracy
Prompt Engineering
After considering how LLMs were built on a fundamental level, we find ourselves analyzing the prompt in the latest attempt and try to form a hypothesis on what may be happening.
The prompt looks something like this when passed to the language model.
######
Answer true or false for each item against the question.
Question: Which of the following mascots can fly?
List: Bronco, Diamondback Rattlesnake, Peacock, Rooster, Blue Jay, Buckeye Nut, 49er, Aztec Warrior, Cow, Tigers, Jaguar, Winged Blue Horse, Minuteman, Bull, Bearcat, Riverboat Gambler, Alligator, Lumberjack, Orange, Boston Terrier
######How Much is Too Much
This isn’t a common format that we come across for a question, but humans can easily figure out the intent here. Perhaps it’s not so easy for LLM’s? Returning to the fundamental idea of predicting word patterns, they would call upon their bank of text that they’re trained on and look for useful patterns. The format that we present to the model isn’t a common or explicit format so it’s feasible that the model may not have encountered text similar to this. How often do people talk of mascots and flying? It’s also unlikely that it’s encountered many documents with questions with this layout.
Perhaps we’re not presenting a common enough pattern to help the LLM respond with the desired results..
The Logic
We’re able to solve this type of problem in our head but we’re questioning if the LLM has the same logic capabilities. When we break down this problem and the steps that we might go through, we imagine that it requires taking a single item from the list and comparing it against the question.
Here’s a sample flow of what one might do in their mind subconsciously to solve this.
Read the question- “Which mascots can fly?”
The word “mascot” really isn’t that important here. It’s a representation for another object so we mostly know to ignore the word mascot.
Take the first word- “Can a Bronco fly?” – Nope.
Next word- “Can a Diamondback Rattlesnake fly?”- Nope
Continue this process
Peacock- “Can a Peacock fly?”- Well yeah. I guess it can.
Remember “Peacock”
Rooster- “Can a Rooster fly?”- Yes.
Remember Peacock and Rooster (even if we have to skim the list once again to remind ourselves)
Eventually- we return the list of mascots that we’re able to recall
What I notice is that I could try to expand the text similarly to the logic above and test if a simplified format might help the model..
Write a simpler question layout
This was quickly testable by typing directly in the Generative AI Studio prompt builder.
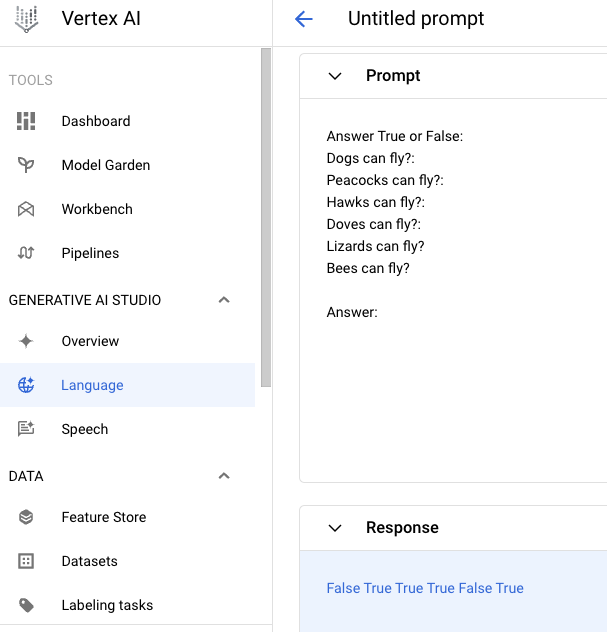
These results look promising. What we’ll need is a control loop that can take our Python list and expand it into a prompt template.
Jinja
Jinja’s a python templating language that first comes to mind when I think of control structures embedded within text docs. I want to programmatically templatize each item on its own line similar to how it’s tested in the Gen AI Studio above. I’m hopeful that it’s a much simpler pattern and easier for the model to recognize and predict.
New jinja function
# @title New Function- Simplify the prompt with a Jinja approach
from langchain.chains.llm import LLMChain
import jinja2
import itertools
def analyze_list_question3(question, mylist):
# print(mylist)
environment = jinja2.Environment()
jinja_template = """
You are a student taking a test.
Analyze the question and write true or false next to every item.
Question: {{jquestion}}
{%for item in provided_list-%}
{{item.strip()}}:
{%endfor%}
"""
template = environment.from_string(jinja_template)
myprompt = template.render(jquestion=question, provided_list=mylist.split(","))
print("&&&&")
print(myprompt)
print("&&&&")
output = llm._call(myprompt)
print("####")
print(output)
print("####")
return outputTest Results
# @title Test Jinja batch function
start_time = time.time()
print(len(results.split(",")))
matched_test = analyze_list_question3(question="Which of these are able to fly?", mylist=results)
print("Following are the mascots which can fly: \n")
print(matched_test)
print("This loop took: {secs} seconds".format(secs=str(time.time() - start_time)))
Following are the mascots which can fly:
Red Fox: False
Musketeer: False
Human and horse: False
Ibis: True
Badger: False
Knight and Horse: False
Bobcat: False
Hawk: True
Lion: False
Torero: False
Viking: False
Hornets: True
Fictional Bird: True
Leopard: False
Greyhound: False
Pilgrim: False
Cow: False
River Hawk: True
Red Hawk: True
Anteater: False
This loop took: 1.591890573501587 secondsThis performs much more consistently than the last version.
Store True Values to a List
Now a small function to grab the values and store them.
Testing
i = 0
true_list = []
m = str(matched_test).split("\n")
for j in m:
# print(j)
pair = j.split(":")
# print (pair)
if (eval(pair[1]) == True):
true_list.append(pair[0])
print(true_list)
['Peacock', 'Rooster', 'Blue Jay', 'Winged Blue Horse']With this list of values, we now know the answer to the original question. “Which mascots can fly?”. Now we can generate a SQL query that references our list of mascots that can fly.