
Lately I feel an elevated sense of anxiety around me, likely due to frequent chatter of layoffs, recession, and general uncertainty. We’re biologically wired to fear losing things so this is an expected reaction. When I notice my stomach turning or my heart beat intensifying, I try to remind myself that gain and loss go hand in hand. Loss creates opportunity for new, exciting things, and overall, I love change. So whatever happens, it’s okay.

It can feel counterintuitive, but In times of elevated anxiety, I find it helpful to do less, reduce the number of tasks that I have in flight, and overall aim to simplify everything. I scale my activities back, challenge recurring meetings to cancel or become more productive, and scrutinize activities that I choose to invest time into. In past roles as developer, platform operator, or other titles, it’s also my responsibility to eliminate waste and ensure the business receives a good return on its investments.

It’s painful to give up our hard earned money for resources that go unused. This series of blogs covers a high level process to review GKE workloads, tune configuration parameters, tighten up our environments, and ensure that we stretch our dollars.
Here’s the high level strategy to tune our clusters in this series:
Cost Optimization Process
Phase 1- Workload Level Efficiencies (this blog)
- Review Metrics: requested vs actual CPU and memory utilization.
- Identify candidate workloads for optimization
- Explore service usage patterns
- Rightsize the workload
- Revisit pod level metrics to validate more efficient utilization
- Summary: GKE Autopilot
Phase 2- Cluster Level Efficiencies
- Review node metrics for requested vs actual utilization
- Review if cluster scales up and down appropriately based on load
- Tune cluster autoscaler and/or node auto provisioner.
- Review node level metrics and observe improvements
- Efficient use of Committed Use Discounts (CUDs)
- Spot instances for appropriate workloads
Phase 3- Extended visibility
- Central collection of resource utilization and recommendations
- Dashboard for multiple project and cluster visibility
Workload Level Efficiencies
Overview
There are two flavors of GKE. GKE standard and GKE Autopilot which is the Google recommended path. On GKE standard, customers manage their workloads along with the underlying infrastructure such as servers and they’re billed by instance type for utilization.
GKE Autopilot simplifies billing and lowers customer management overhead because infrastructure is managed by Google SREs. Customers focus on their applications and are charged by cpu, memory, and storage from deployment manifests. Additional benefits of Autopilot will be explored more in depth in a future post.
The image below is divided into two parts, the upper half is the workload layer and the bottom half is the infrastructure layer.

GKE standard clusters have a larger domain of responsibility that falls on the customer. In both cluster types, workload level optimizations are the responsibility of the application team and they’re the foundation upon which we reduce costs. You can see the domain of customer responsibility when running GKE Autopilot and standard clusters on the left in the image below.
This first post in our series will focus on workload layer optimization.

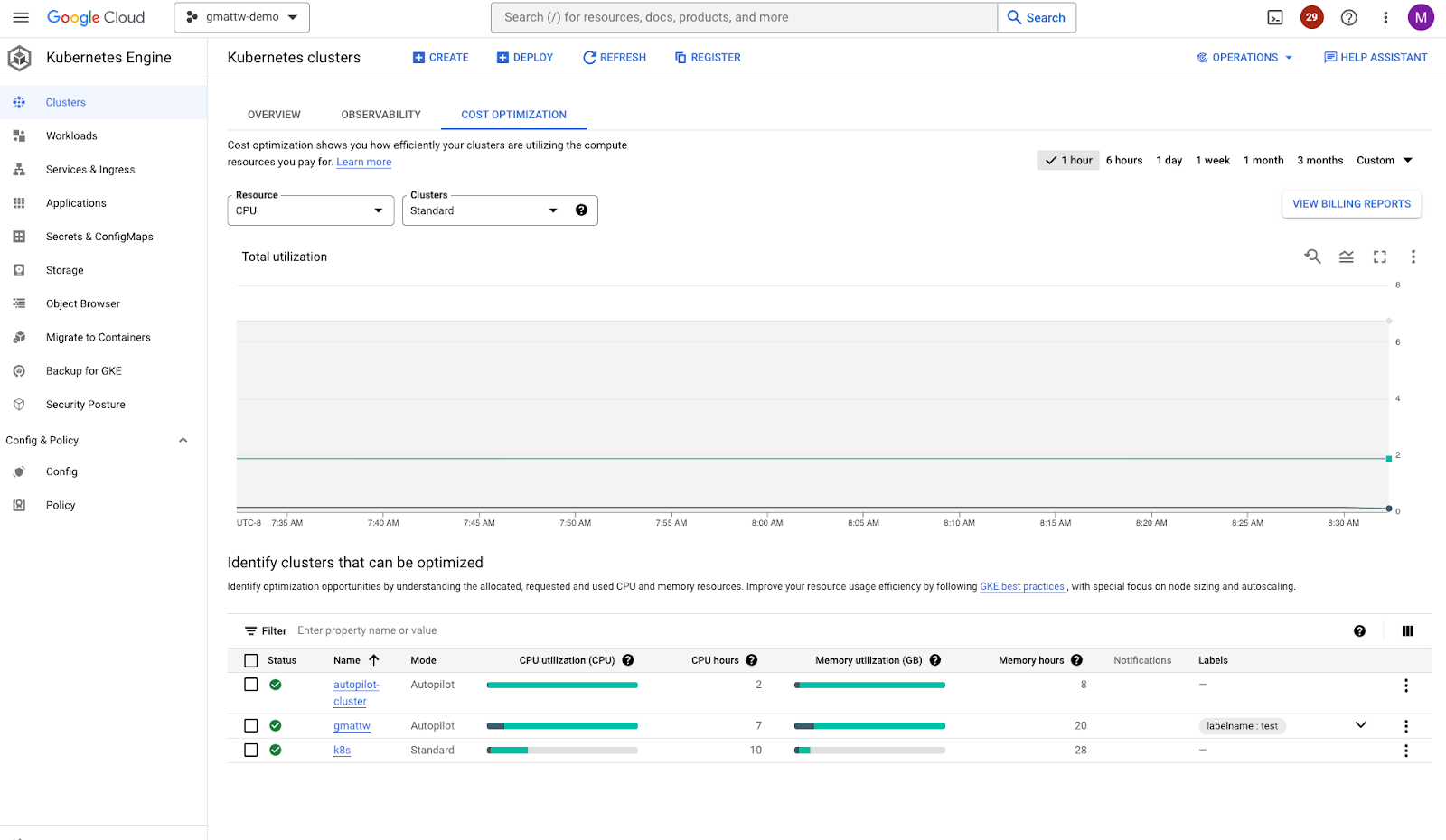
Review Metrics: requested vs actual CPU and memory utilization.
Open the GKE clusters dashboard. At the top, click “Cost Optimization”. On the bottom, there’s a list of clusters with visualizations showing resource utilization. Dark green is actual usage while lighter green represents requested resources and gray is total capacity if running on GKE standard. In the image below, actual usage is low on all clusters. Also note that only the ‘k8s’ cluster has a gray bar because the other two clusters use Autopilot where the nodes are managed by Google.
Identify candidate workloads for optimization
For additional insight, open the GKE workloads dashboard. At the top of the page, the default view shows “Overview”, click the “Cost Optimization” tab.

Along the top are filters for cluster(s) and namespace(s). The initial large graph shows utilization efficiency for CPU across selected cluster(s) and namespace(s). (Actual vs Requested) The ‘Resource’ pull down can also be changed to gain insight into memory utilization.
At the bottom, a visual for each running workload with the applied filter is shown. Dark green represents actual usage and lighter green is requested utilization. From first glance, one can see that actual usage is low across all services.

In this example, we click the balancereader service for more details.

Explore service usage patterns
The overview dashboard for the service shows utilization metrics. At the bottom of the image, the number of ‘Replicas’ that are running is displayed. In the below example, there’s a single replica. It’s common to see more than one replica for added redundancy but if the number of replicas for this service seems high while our utilization is low, we should consider running fewer replicas so that we increase the utilization of existing pods.
Pod level scaling can be manually edited via the Actions/Scale/Edit Replicas menu.

If in a dev/test environment where replicas can be manually edited, optionally edit the number of replicas and press ‘scale’.

The number of replicas should ideally be managed by the HorizonalPodAutoscaler (HPA). If the HPA is configured and too many replicas are running, tuning and testing is required to improve efficiency. This process typically involves running a load test against our services and it can get more complex than can be covered with this general post. I’ll consider a future blog post to show a process for efficient HPA tuning. For now , if you need help with the HPA, engage the app team for a hand or contact your Google account team for guidance.
Back to the sample application, there’s a single replica running, therefore HPA is not an issue and the deployment needs to be right-sized.
Which recommendations should I use?
** Important **
Remember that Google recommendations for application right sizing are based on the behavior observed in your environment. Keep this in mind when you choose which recommendations to use!
If we choose an application in a test environment that nobody uses, we’re going to see very low CPU and memory utilization, perhaps 1% CPU & <20% memory. In this case, our recommendation engine would tell us that this test environment is underutilized and that we should scale our application down to save money.
If we take the same recommendation from the test environment and try to run it in production, our application will likely fall over quickly with real customer requests coming to it.
As a general rule of thumb, I advise to primarily look at recommendations that are running with actual customer traffic in a production environment. Ignore recommendations for environments that are for testing, staging, or are generally underutilized.
If we want to include ‘right sizing’ as part of our test or QA process before production, we should have a load test running which replicates real customer traffic patterns to create a realistic load on our applications. A load test should generate a similar sizing recommendation.
Consider your application traffic patterns
** Important **
Along this same thought pattern of choosing which recommendations to use:
Know your application!
Analyze historical traffic patterns for each service that you want to go through the right sizing process for. Consider if the service has a peak time of day in which is it stressed more than other times of day. Some services may only get called once a month for example.
Be sure to choose recommendations that are generated during peak performance periods of our applications.
Be conservative when making changes
** Important **
As a general rule, try to make small changes and observe behavior to ensure expected outcomes and that desired results are being achieved. When your application has 8 vCPU’s allocated to it and the recommendation engine suggests allocating ¼ vCPU, be weary!
Make changes to recommended allocations in small increments!
Reviewing recommendations for an application
Under the Actions menu, select ‘Scale’, and then ‘Edit resource requests’

A resource utilization dashboard is presented and on the top, utilization can be viewed over varying window sizes. Use these window sizes to ensure that recommendations that we choose to explore are for a peak time of utilization and not while a service is idle.

Click through a few shorter and longer time frames to see if resource underutilization is consistent or if it has times of higher load. When ‘right sizing’ resources it’s important to understand utilization patterns of the applications in question. Some applications may experience steady utilization, others may sit idle for many hours a day or even days per month. Keep this in mind when reviewing recommendations and the intervals over which these are being calculated. We want to ‘right size’ our resource settings based on a normal to heavy load and not during idle time.

Rightsize the workload
This application looks consistently underutilized so move next to the section below “Adjust resource requests and limits”. Current settings from the deployment/pod manifest are presented. Highlighted in the image below, Google Cloud recommends that CPU and memory for this application can be reduced.


The value is a suggestion that we can try but I suggest a conservative approach to making changes. A lower value can be entered to observe how the application behaves and how utilization patterns change. Accept recommended values by pressing “Apply Latest Suggestions” or enter specific values and then press ‘Save Changes’ to apply them.

In a staging or production environment, these values should be changed through a standard change control process utilizing source control. Note that for Autopilot clusters, there are minimum values supported for each resource type. The most up to date information on minimum increments can be found here:
https://cloud.google.com/kubernetes-engine/pricing
Summary Phase 1: Optimizing the workload
After repeating this process to optimize request settings for your workloads, the workload optimization phase is complete. For GKE Autopilot users, you’re already saving money!
With GKE standard, there might be some cost savings at this point but completion of phase 1 sets up a smooth phase 2 when we visit cluster level optimizations where we save money.
This week’s exploration of workload level optimization helps free up CPU, memory, and costly resources. For those running GKE standard clusters, we’ll move next into Phase 2 where we further lock in the savings. If you’re still running GKE standard, ask yourself:
“Is there a good reason that you’re not using GKE Autopilot?”
Keep an eye out for part 2 of the blog where we dig into additional details on cluster level tuning.